🧾 Prerequisites
You need to have Ollama installed on your system. You can find installation instructions and source code at:⚠️ Note: While we support self-hosted LLMs, you will get significantly better responses with more powerful models like GPT-4.
🚀 Getting Started with Ollama
- Install Ollama following the instructions for your operating system
- Start a model using the command:
- Verify the API works with a test request:
⚙️ Set Up Hymalaia with Ollama
- Navigate to the LLM page in the Hymalaia Admin Panel
- Add a Custom LLM Provider with the following identifiers:
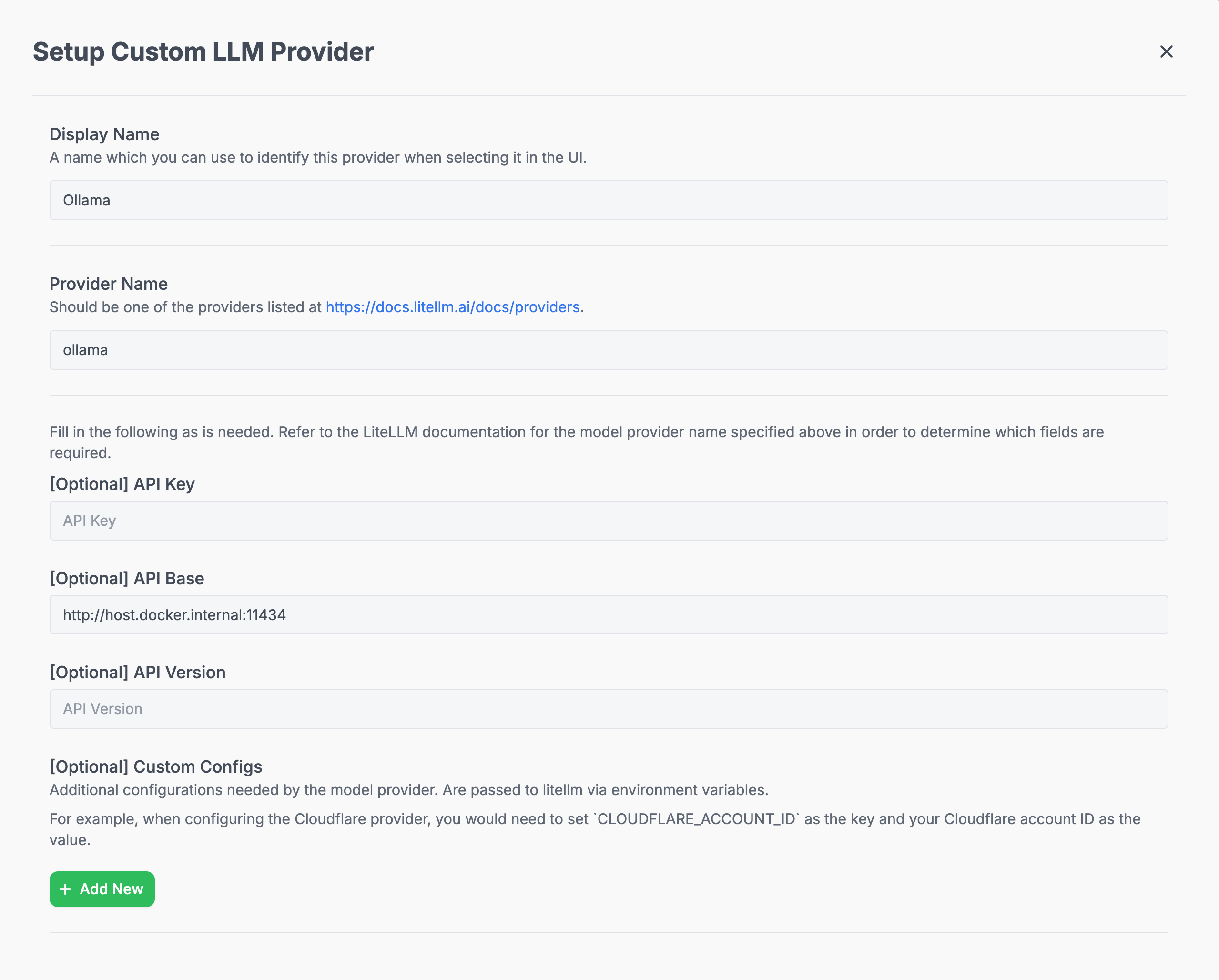
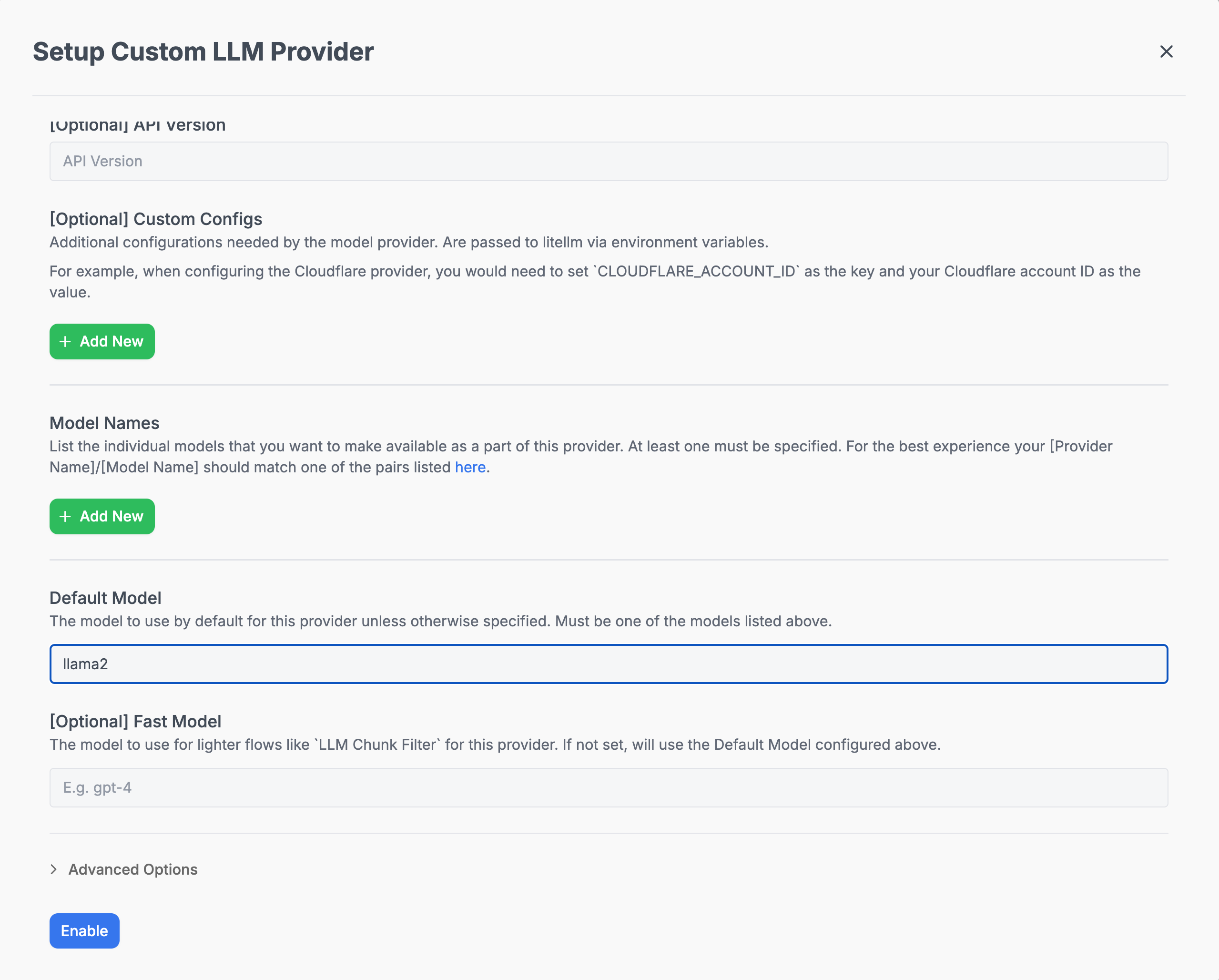
🔍 Note: For the API Base, when using Docker, point tohost.docker.internalinstead oflocalhost(e.g.,http://host.docker.internal:11434).
🛠️ Environment Configuration
You may want to adjust these environment variables to optimize for locally hosted LLMs:For more detailed setup and environment configuration examples, refer to the Model Configs.